
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- 자료구조
- python
- 코딩테스트준비
- 크루스칼
- 암호학
- spring
- Queue
- generic class
- dfs
- 가상컴퓨팅
- DB
- 99클럽
- Java
- 자바의정석
- dbms
- jsp
- JPA
- mybatis
- sql
- BFS
- 개발자취업
- javascript
- 공개키 암호화
- Algorithm
- 코테
- js
- 코딩테스트
- 항해99
- til
- 알고리즘
- Today
- Total
목록개발 공부/Database (17)
PLOD
 [DB] Query Optimization
[DB] Query Optimization
query optimization SQL 쿼리가 주어질 때 최단 시간내에 출력될 수 있는 최적의 query plan을 선택하는 작업, 특히 쿼리가 복잡한 경우 일반적으로 주어진 쿼리를 처리하기 위해 많은 전략에서 가장 효율적인 쿼리 평가 계획을 선택하는 프로세스 평가 계획은 각 작업에 사용되는 알고리즘과 작업 실행이 조정되는 방법을 정확하게 정의한다. query optimize를 하는 이유 : temporary result의 사이즈를 줄이기 위해 *cost-based query optimization 1) 동등성 규칙을 사용하여 논리적으로 동등한 식을 생성 2) 결과 식에 주석을 달아 대체 쿼리 계획을 가져온다. 3) 예상 비용을 기준으로 가장 저렴한 요금제 선택 평가 계획을 세울때는 관계에 대한 통계적..
 [DB] Query Processing + query cost
[DB] Query Processing + query cost
- DBMS 에서 query를 처리하는 과정 1. 입력받은 쿼리를 parser와 translator 가 relational-algebra 형태로 변환한다,(query -> relational - algebra) 2. optimizer가 데이터의 통계정보를 바탕으로 쿼리 실행 계획을 세운다 3. evaluation engine이 세워진 계획을 바탕으로 쿼리를 실행하여 결과를 반환한다. - Query Optimization : 모든 평가 계획 들 중 가장 적은 금액을 선택한다. 가격은 tuple의 개수 , tuple의 사이즈 같은 정보들로 결정된다. - Query Cost : Cpu, network도 가격에 영향을 주지만 영향을 주는 범위가 매우적다 , seek의 개수, seek-cost, block -re..
 [DB]실무 데이터 모델링 프로세스
[DB]실무 데이터 모델링 프로세스
1. 데이터 모델링의 3가지 관점 1) 데이터 관점 : 업무가 어떤 데이터와 관련이 있는지 또는 데이터 간의 관계는 무엇인지 모델링 2) 프로세스관점 : 업무에서 실제 하는 일은 무엇인지 또는 어떻게 해야 하는지에 대해 모델링 하는 방법 3) 상관관점 : 업무가 처리하는 일의 방법에 따라 데이터는 어떻게 영향을 받고 있는지 모델링 하는 방법
 [DB] E-R diagram
[DB] E-R diagram
데이터 베이스 설계 = 제약조건 집합 + 관계형 데이터베이스 집합 1. 데이터 베이스 설계 과정 초기 단계는 예상 데이터베이스 사용자의 데이터 요구를 완전히 특정화 하는 것이다. 다음으로는 ,설계자는 데이터 모델을 선택하고 선택한 데이터 모델의 개념을 적용함으로써 이러한 요구사항을 데이터 베이스의 개념 스키마로 변환한다.(기업의 기술적 요구) 마지막으로 추상 데이터 모델에서 데이터 베이스를 구현하는 단계로 넘어간다. - logical design (논리적 디자인) : 데이터베이스 스키마를 결정한다. 데이터 베이스 디자인은 릴레이션 스키마의 집합에서 좋은 '관계모음'을 요구한다. - Physical design(물리적 디자인) : 데이터 베이스의 틀을 결정한다. 좋은 데이터베이스 설계를 위해서는 불완전성과..
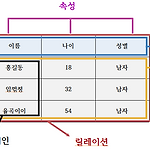 [DB] schema 와 instance
[DB] schema 와 instance
schema : 데이터베이스의 논리적 구조 , 데이터베이스에 저장되는 제약조건을 정리한 것 instance : 특정 시점에서 데이터베이스의 실제내용, 무슨말이냐면 데이터 베이스에 실제 저장된 값을 의미한다
 [DB Modeling] Re-introduction to Database
[DB Modeling] Re-introduction to Database
DB : 영속적인 데이터들의 집합(테이블)들의 통합 DBMS의 장단점 - 장점 1. 데이터 중복의 최소화 2. 데이터의 공유 3. 일관성 유지 4. 무결성 유지 5. 보안 보장 6. 표준화 용이 7. 전체 데이터 요구의 조정 - 단점 1.비용의 문제 2.프로그램의 복잡화 3. 성능상의 오버헤드 데이터 독립성 : 하위단계의 데이터 구조가 변경되더라도 상위단계에 영향을 미치지 않는 것, 데이터 베이스는 view level(외부단계) 과 logical level(논리단계) , physical level(내부적 단계)로 이루어져 있다. 하위단계인 데이터 구조의 변화로 인한 영향을 프로그램에 미치지 않도록 하는 것을 의미한다. 즉 데이터 표현 방법이나 저장 위치가 변하더라도 응용 프로그램에는 아무런 영향을 미치지..