
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- Algorithm
- 가상컴퓨팅
- JPA
- sql
- 코테
- jsp
- 항해99
- dbms
- 코딩테스트
- 코딩테스트준비
- javascript
- 위상정렬
- 자료구조
- 99클럽 #코딩테스트준비 #개발자취업 #항해99 #til
- 공개키 암호화
- til
- BFS
- 99클럽
- Java
- python
- 알고리즘
- DB
- js
- generic class
- 자바의정석
- 정렬
- 크루스칼
- 개발자취업
- Sort
- spring
- Today
- Total
PLOD
[Hadoop] YARN : Yet Another Resource Negotiator 본문
[Hadoop] YARN : Yet Another Resource Negotiator
훌룽이 2022. 12. 15. 12:30
* YARN : Hadoop 프로젝트의 분산 환경에서의 자원관리를 담당하는 프레임워크
기존의 hadoop에서 하나의 클러스터에서 다양한 하둡 에코시스템이 적절히 시스템 자원을 할당받고, 할당된 자원이 모니터링되고 해제되는 체계가 미흡한 리소스 자원 관리 문제(hadoop이 가지고 있던 SPOF(JobTracker의 메모리 이슈)인 namenode 이중화문제(자원 할당과 작업 스케줄링이 일원화 되어있음,))그리고 MapReduce 기반이 아닌 시스템은 자원 공유가 불가능한 기존의 리소스 관리 방식, datanode 블록들이 하나의 namespace만 사용하는 데 따르는 단점과 성능개선 요청인 HDFS Fereration 으로 인한 hadoop의 안정성문제로 인해 hadoop 1.0의 무제가 대두되기 시작했다.
그래서 나오게된게 YARN을 지원하는 hadoop 2.0이다. YARN은 기존의 hadoop 1.0 에서 MapReduce API로만 개발되던 어플리케이션만 실행되는 한 것을 다른 종류의 API도 실행할 수 있게 하였다. YARN은 기존의 Hadoop 1.0이 Map과 Reduce라는 정해진 구조 외에 다른 알고리즘을 지원하는데 한계를 깨기 위해 클러스터를 확장 하였다. 또 기존의 리소스 자원문제를 해결하기 위해 JobTracker의 주요기능을 추상화 하였다.
* Hadoop 1.0 의 문제점
1) 리소스 자원 관리 문제(SPOF ,namenode 이중화 문제)
2) MapReduce 리소스 관리 방식
3) hadoop의 안정성 문제
* YARN의 특징
1) 확장성 :YARN은 수용가능한 단일 클러스터의 규모를 10000노드 까지 확대하였으며 실행가능한 데이터 처리 작업의 개수도 증가
2) 클러스터 활용 개선 : 자원 관리를 위한 별도의 컴포넌트 개발(ResourceManager) , 클러스터 리소스를 요청하고 작업하기 위한 API를 제공한다. 또 사용자가 상위 순준 API를 쓰기 및 리소스 관리등 세부정보를 숨긴다.
3) 워크로드 확장 : MapReduce 이외에도 다른 API 실행 가능
4) MapReduce 호환성 : 기존의 MapReduce code를 수정하지 않아도 실행 가능
* YARN 은 기능적으로 두 부분으로 나뉜다.
1) platform layer : 리소스를 관리하는 Resource Manager 과 Node Manager가 있다.
2) framework layer : API를 실행하는 ApplicationMaster가 있다.
* YARN excution Model
1) YARN API 실행 : 클라이언트가 Resource Manager 에게 Application Master에게 실행하라고 명령
2) Application Master 실행 : Node Manager을 찾은 후 container 안에서 Application Master가 실행하도록 함
3) Application Master가 Resource Manager에게 더 많은 container를 요청 (CPU, Memory)
4) 구별 작업 실행
* MapReduce Job Run
1) Scalability (확장성) : Job Tracker와 달리 애플리케이션의 각 인스턴스에는 전용 애플리케이션 마스터가 있다
2) Availabilty (유용성) : 리소스 관리자를 위해 High Availability(HA)를 제공한 다음 YARN Application 을 위해 HA(고가용성)를 제공
3) Utilization(활용도) : container 관리를 통해 YARN의 리소스는 세분화 되어있음
* Schedulers in YARN : 기본값은 Capacity Schedular로 설정되있다
1) FIFO schedular
선입 선출 방식, 먼저 도착한 job이 먼저 시행된다.
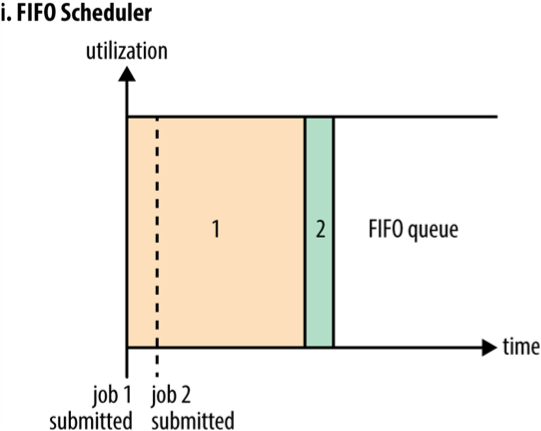
2) Capacity Scheduler
YARN의 default scheduler , 조직 라인을 따라 Hadoop 클러스터를 공유할 수 있다. 각 조직에는 전체 클러스터의 용량이 할당하고 각 조직은 계층적 방식으로 더 분할 될 수 있다. 대기열 내에서 응용프로그램은 FIFO 방식으로 scheduling 한다. 단일 작업이 대기열의 용량보다 더 많은 리소스를 사용하지 않는다. 대기열에 작업이 두개이상 있고 사용가능한 유휴 리소스가 있는 경우 용량 스케줄러는 대기열의 작업에 예비 리소스 할당 가능(queue elasticity)

정상적인 작동에서 capacity scheduler는 강제로 컨테이너를 제거하거나 먼저 선점하지 않는다. 대기열이 존재해야 함 (제출 제한 시간에 오류가 발생)
3) Fair Scheduler
실행 중인 모든 응용 프로그램이 동일한 리소스 공유를 받도록 리소스 할당을 시도한다. 작업을 시작하는데 걸리는 시간을 보다 예측 가능하게 만들기 위해 공정 스케줄러의 선점을 지원(preemption:선취권), preemption은 공유자원 보다 더 많이 사용할 수 있게 하지만 전체 클러스터 효율성을 저하시킨다.

* Dominant Resource Fairness(DRF)
메모리와 같은 단일 리소스 유형만 예약되어 있는 경우 용량 또는 공정성의 개념을 쉽게 결정 할 수 있다. 또 각 사용자의 주요 리소스를 살펴보고 클러스터 사용량을 측정하는 데 사용된다 .

'computer science > Cloud computing' 카테고리의 다른 글
| [k8s]kubernetes(쿠버네티스) (0) | 2024.10.18 |
|---|---|
| [Docker] docker와 docker - compose (0) | 2024.08.14 |
| [Spark] Apache - Spark (1) | 2022.12.15 |
| [MapReduce] HIVE and pig (0) | 2022.12.15 |
| [HDFS] MapReduce : simplified Data Processing on Large Clusters (0) | 2022.11.03 |



